You start building your new project. You’ve heard good things about Postgres, so you choose it as your database. As advertised, it proves to be a satisfying tool and progress is good. You put your project into production for the first time and like you’d hoped, things go smoothly as Postgres turns out to be well-suited for production use as well.
The first few months go well and traffic continues to ramp up, when suddenly a big spike of failures appears. You dig into the cause and see that your application is failing to open database connections. You find this chilling artifact littered throughout your logs:
FATAL: remaining connection slots are reserved for
non-replication superuser connections
This is one of the first major operational problems that new users are likely to encounter with Postgres, and one that might prove to be frustratingly persistent. Like the error suggests, the database is indicating that its total number of connection slots are limited, and that the limit has been reached.
The ceiling is controlled by the max_connections key in
Postgres’ configuration, which defaults to 100. Almost
every cloud Postgres provider like Google Cloud Platform or
Heroku limit the number pretty carefully, with the largest
databases topping out at 500 connections, and the smaller
ones at much lower numbers like 20 or 25.
At first sight this might seem a little counterintuitive. If the connection limit is a known problem, why not just configure a huge maximum to avoid it? As with many things in computing, the solution isn’t as simple as it might seem at first glance, and there are a number of factors that will limit the maximum number of connections that it’s practical to have; some obvious, and some not. Let’s take a closer look.
The practical limits of concurrency
The most direct constraint, but also probably the least important, is memory. Postgres is designed around a process model where a central Postmaster accepts incoming connections and forks child processes to handle them. Each of these “backend” processes starts out at around 5 MB in size, but may grow to be much larger depending on the data they’re accessing 1.

Since these days it’s pretty easy to procure a system where memory is abundant, the absolute memory ceiling often isn’t a main limiting factor. One that’s more subtle and more important is that the Postmaster and its backend processes use shared memory for communication, and parts of that shared space are global bottlenecks. For example, here’s the structure that tracks every ongoing process and transaction:
typedef struct PROC_HDR
{
/* Array of PGPROC structures (not including dummies for prepared txns) */
PGPROC *allProcs;
/* Array of PGXACT structures (not including dummies for prepared txns) */
PGXACT *allPgXact;
...
}
extern PGDLLIMPORT PROC_HDR *ProcGlobal;
Operations that might happen in any backend requires walking the entire list of processes or transactions. Adding a new process to the proc array necessitates taking an exclusive lock:
void
ProcArrayAdd(PGPROC *proc)
{
ProcArrayStruct *arrayP = procArray;
int index;
LWLockAcquire(ProcArrayLock, LW_EXCLUSIVE);
...
}
Likewise, GetSnapshotData is often called multiple times
for any operation and needs to loop through every other
process in the system:
Snapshot
GetSnapshotData(Snapshot snapshot)
{
ProcArrayStruct *arrayP = procArray;
...
/*
* Spin over procArray checking xid, xmin, and subxids. The goal is
* to gather all active xids, find the lowest xmin, and try to record
* subxids.
*/
numProcs = arrayP->numProcs;
for (index = 0; index < numProcs; index++)
{
...
}
}
There are a few such bottlenecks throughout the normal paths that Postgres uses to work, and they are of course in addition to the normal contention you’d expect to find around system resources like I/O or CPU.
The cumulative effect is that within any given backend, performance is proportional to the number of all active backends in the wider system. I wrote a benchmark to demonstrate this effect: it spins up a cluster of parallel workers that each use their own connection to perform a transaction that inserts ten times, selects ten times, and deletes ten times before committing 2. Parallelism starts at 1, ramps up to 1000, and timing is measured for every transaction. You can see from the results that performance degrades slowly but surely as more active clients are introduced:
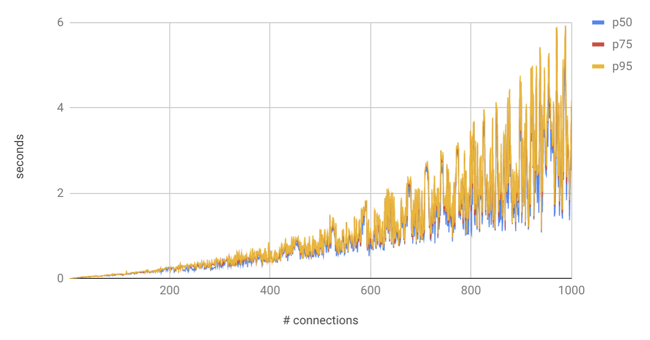
So while it might be a little irking that platforms like Google Cloud and Heroku limit the total connections even on very big servers, they’re actually trying to help you. Performance in Postgres isn’t reliable when it’s scaled up to huge numbers of connections. Once you start brushing up against a big connection limit like 500, the right answer probably isn’t to increase it – it’s to re-evaluate how those connections are being used to and try to manage them more efficiently.
Techniques for efficient connection use
Connection pools
A connection pool is a cache of database connections,
usually local to a specific process. Its main advantage is
improved performance – there’s a certain amount of
overhead inherent to opening a new database connection in
both the client and the server. After finishing with a
connection, by checking it back into a pool instead of
discarding it, the connection can be reused next time one
is needed within the application. Connection pooling is
built into many database adapters including Go’s
database/sql, Java’s JDBC, or
Active Record in Ruby.

Connection pools also help manage connections more efficiently. They’re configured with a maximum number of connections that the pool can hold which makes the total number of connections that you can expect a single deployed node to use deterministic. By writing application workers to only acquire a connection when they’re serving a request, those per-node pools of connections can be shared between a much larger pool of workers.
A limitation of connection pools is that they’re usually only effective in languages that can be deployed within a single process. Rails implements a connection pool in Active Record, but because Ruby isn’t capable of real parallelism, it’s common to use forking servers like Unicorn or Puma. This makes those connection pools much less effective because each process needs to maintain its own 3.
Minimum viable checkouts
For any given span of work, very often it’s possible to identify a critical span in the middle where core domain logic is being run, and where a database connection needs to be held. To take an HTTP request for example, there’s usually a phase at the beginning where a worker is reading a request’s body, decoding and validating its payload, and performing other peripheral operations like rate limiting before moving on to the application’s core logic. After that logic is executed there’s a similar phase at the end where it’s serializing and sending the response, emitting metrics, performing logging, and so on.

Workers should only have a connection checked out of the pool while that core logic is executing. This minimum viable checkout technique maximizes the efficient use of connections by minimizing the amount of time any given worker holds one, allowing a pool of connections to be feasibly shared amongst a much larger pool of workers. Idle workers don’t hold any connections at all.
Releasing connections around foreign mutations
I’ve written previously about breaking units of application work into atomic phases around where an application is making requests to foreign APIs. Utilization can be made even more efficient by making sure to release connections back to the pool while that slow network I/O is in flight (an application should not be in a transaction while mutating foreign state anyway), and reacquire them afterwards.
PgBouncer & inter-node pooling
Connection pools and minimum viable checkouts will go a long way, but you may still reach a point where a hammer is needed. When an application is scaled out to many nodes, connection pools maximize the efficient use of connections local to any of them, but can’t do so between nodes. In most systems work should be distributed between nodes roughly equally, but because it’s normal to use randomness to do that (through something like HAProxy or another load balancer), and because work durations vary, an equal distribution of work across the whole cluster at any given time isn’t likely.
If we have N nodes and M maximum connections per node,
we may have a configuration where N × M is greater than
the database’s max_connections to protect against the
case where a single node is handling an outsized amount of
work and needs more connections. Because nodes aren’t
coordinating, if the whole cluster is running close to
capacity, it’s possible for a node trying to get a new
connection to go over-limit and get an error back from
Postgres.
In this case it’s possible to install PgBouncer to act as a global pool by proxying all connections through it to Postgres. It functions almost exactly like a connection pool and has a few modes of operation:
Session pooling: A connection is assigned when a client opens a connection and unassigned when the client closes it.
Transaction pooling: Connections are assigned only for the duration of a transaction, and may be shared around them. This comes with a limitation that applications cannot use features that change the “global” state of a connection like
SET,LISTEN/NOTIFY, or prepared statements 4.Statement pooling: Connections are assigned only around individual statements. This only works of course if an application gives up the use of transactions, at which point it’s losing a big advantage of using Postgres in the first place.

Transaction pooling is the best strategy for applications
that are already making effective use of a node-local
connection pool, and will allow such an application that’s
configured with an N × M greater than max_connections
to closely approach the maximum possible theoretical
utilization of available connections, and to also avoid
connection errors caused by going over-limit (although
delaying requests while waiting for a connection to become
available from PgBouncer is still possible).
Probably the more common use of PgBouncer is to act as a node-local connection pool for applications that can’t do a good job of implementing their own, like a Rails app deployed with Unicorn. Heroku, for example, provides and recommends the use of a standardized buildpack that deploys a per-dyno PgBouncer to accomplish this. It’s a handy tool to cover this case, but it’s advisable to use a more sophisticated technique if possible.
Connections as a resource
There was a trend in frameworks for some time to try and simplify software development for their users by abstracting away the details of connection management. This might work for a time, but in the long run anyone deploying a large application on Postgres will have to understand what’s happening or they’re likely to run into trouble. It’ll usually pay to understand them earlier so that applications can be architected smartly to maximize the efficient use of a scarce resource.
Developers should be aware of how many connections each
node can use, how many connections a cluster can use by
multiplying that number by the number of nodes, and where
that total sits relative to Postgres’ max_connections.
It’s common to hit limits during a deploy because a
graceful restart spins up new workers or nodes before
shutting down old ones, so know expected connection numbers
during deployments as well.
Finally, although we’ve talked mostly about Postgres here, there will be practical bottlenecks like the ones described here in any database, so these techniques for managing connections should be widely portable.