An alarm goes off and open your laptop. Your job queue has spiked to 10,000 jobs and is still growing rapidly. The bloated queue means that internal components are not receiving critical updates which will eventually compromise the health of the whole system. You start to investigate. The worker processes look healthy and jobs are being worked in a timely manner. Everything else looks normal. After close to an hour feeling around the system you notice a transaction that another team has opened for analytical purposes on one of your database followers. You promptly send it a SIGINT. The queue’s backlog evaporates in the blink of an eye and normalcy returns.
Long running databases transactions appear to be the culprit here, but how exactly can they have such a significant impact on a database table? And so quickly no less?
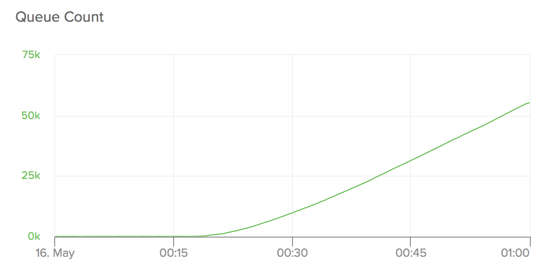
The figure below shows a simulation of the effect. With a relatively high rate of churn through the jobs table (roughly 50 jobs a second here), the effect can be reproduced quite quickly. After manifesting, it only takes about 15 minutes to worsen to the point where recovery is hopeless.
Why put a job queue in Postgres?
Your first question may be: why put a job queue in Postgres at all? The answer is that although it may be far from the use case that databases are designed for, storing jobs in a database allows a program to take advantage of its transactional consistency; when an operation fails and rolls back, an injected job rolls back with it. Postgres transactional isolation also keeps jobs invisible to workers until their transactions commit and are ready to be worked.
Without that transactional consistency, having jobs that are worked before the request that enqueued them is fully committed is a common problem. See the Sidekiq FAQ on this subject for example.
As we’ll see below, there are very good reasons not to use your database as a job queue, but by following a few key best practices, a program can go pretty far using this pattern.
Building a test bench
We originally noticed this problem in production, but the first step for us to be able to check any potential solutions is to be able to reliably reproduce it in a controlled environment. For this purpose, we wrote the que-degradation-test, a simple program with three processes:
- A job producer.
- A job worker.
- A “longrunner” that starts a transaction and then sits idle in it.
Like we hoped, the program was easily able to reproduce the problem and in a reliable way. All the charts in this article are from test data produced by it.
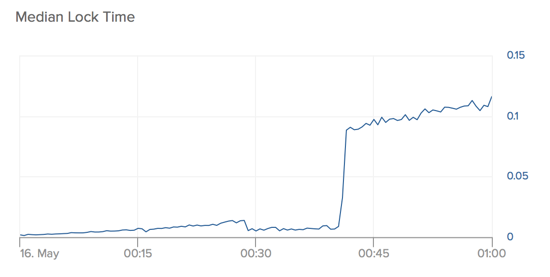
Slow lock time
The first step into figuring out exactly what’s going wrong is to find out what exactly about the long running transaction is slowing the job queue down. By looking around at a few queue metrics, we quickly find a promising candidate. During stable operation, a worker locking a job to make sure that it can be worked exclusively takes on the order of < 0.01 seconds. As we can see in the figure below though, as the oldest transaction gets older, this lock time escalates quickly until it’s 15x that level at times of 0.1 s and above. As the difficulty to lock a job increases, workers can lock fewer of them in the same amount of time. Left long enough, the queue will eventually reach a point where more jobs are being produced than being worked, leading to a runaway queue.
Locking algorithms
We’d originally been using a library called Queue Classic (QC) to run our job queue. We started to suspect that its relatively inefficient locking mechanism might be the source of our trouble, so we moved over to another package called Que (pronounced “kay”) which is known to be faster. But to our chagrin, we found that the problem still existed, even if its better overall performance did seem to help stave it off for a little bit longer. We’ll be examining Que in detail here, but it’s worth nothing that both of these systems are susceptible to the same root problem.
Inspecting Que’s source code, we see that it uses this algorithm to lock a job:
WITH RECURSIVE jobs AS (
SELECT (j).*, pg_try_advisory_lock((j).job_id) AS locked
FROM (
SELECT j
FROM que_jobs AS j
WHERE queue = $1::text
AND run_at <= now()
ORDER BY priority, run_at, job_id
LIMIT 1
) AS t1
UNION ALL (
SELECT (j).*, pg_try_advisory_lock((j).job_id) AS locked
FROM (
SELECT (
SELECT j
FROM que_jobs AS j
WHERE queue = $1::text
AND run_at <= now()
AND (priority, run_at, job_id) > (jobs.priority, jobs.run_at, jobs.job_id)
ORDER BY priority, run_at, job_id
LIMIT 1
) AS j
FROM jobs
WHERE jobs.job_id IS NOT NULL
LIMIT 1
) AS t1
)
)
SELECT queue, priority, run_at, job_id, job_class, args, error_count
FROM jobs
WHERE locked
LIMIT 1
This might look a little scary, but after understanding how to read a recursive Postgres CTE, it can be deconstructed into a few more easily digestible components. Recursive CTEs generally take the form of <non-recursive term> UNION [ALL] <recursive term> where the initial non-recursive is evaluated and acts as an anchor to seed the recursive term. As noted in the Postgres documentation, the query is executed with these basic steps:
- Evaluate the non-recursive term. Place results into a temporary working table.
- So long as the working table is not empty, repeat these steps:
- Evaluate the recursive term, substituting the contents of the working table for the recursive reference. Place the results into a temporary intermediate table.
- Replace the contents of the working table with the contents of the intermediate table and clear the intermediate table.
In the locking expression above, we can see that our non-recursive term finds the first job in the table with the highest work priority (as defined by run_at < now() and priority) and checks to see whether it can be locked with pg_try_advisory_lock (Que is implemented using Postgres advisory locks because they’re atomic and fast). If it was locked successfully, the condition and limit outside of the CTE (WHERE locked LIMIT 1) stop work and return that result. If the lock was unsuccessful, it recurses.
Each run of the recursive term does mostly the same thing as the non-recursive one, except that an additional predicate is added that only examines jobs of lower priority than the ones that have already been examined (AND (priority, run_at, job_id) > (job.priority, job.run_at, job.job_id)). By recursing continually given this stable sorting mechanism, jobs in the table are iterated one-by-one and a lock is attempted on each.
Eventually one of two conditions will be met that ends the recursion:
- A job is locked, iteration is stopped by
LIMITcombined with the check onlocked, and the expression returns a successfully locked row. - If there are no more candidates to lock, the select from
que_jobswill come up empty, which will automatically terminate the expression.
Taking a closer look at the jobs table DDL we see that its primary key on (priority, run_at, job_id) should ensure that the expression above will run efficiently. We may be able to improve that somewhat by introducing some randomness to reduce contention, but that’s unlikely to help with the multiple order of magnitude performance degradation that we’re seeing, so let’s move on.
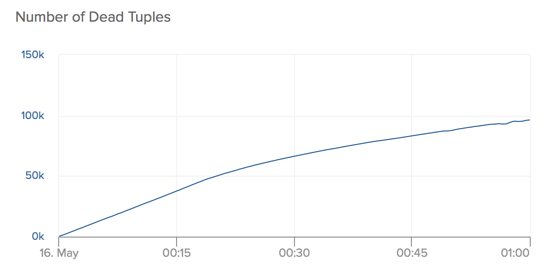
Dead tuples
By continuing to examine test data, we quickly notice another strong correlation. As the age of the oldest transaction increases, the number of dead tuples in the jobs table grows continually. The figure below shows how by the end of our experiment, we’re approaching an incredible 100,000 dead rows.
Automated Postgres VACUUM processes are supposed to clean these up, but by running a manual VACUUM, we can see that they can’t be removed:
=> vacuum verbose que_jobs;
INFO: vacuuming "public.que_jobs"
INFO: index "que_jobs_pkey" now contains 247793 row versions in 4724 pages
DETAIL: 0 index row versions were removed.
3492 index pages have been deleted, 1355 are currently reusable.
CPU 0.00s/0.02u sec elapsed 0.05 sec.
INFO: "que_jobs": found 0 removable, 247459 nonremovable row versions in 2387 out of 4303 pages
DETAIL: 247311 dead row versions cannot be removed yet.
...
Notice the last line “247311 dead row versions cannot be removed yet”. What this error message is trying to say is that these rows can’t be removed because they’re still potentially visible to another process in the system. To understand this more fully, we’ll have to dig a little further into the Postgres MVCC model.
Postgres MVCC
To guarantee transaction isolation (that’s the “I” in “ACID”), Postgres implements a concurrency control model called MVCC (Multiversion Concurrency Control) that ensures that each ongoing SQL statement sees a consistent snapshot of data regardless of what changes may have occurred on the underlying data. By extension, that means that rows that are deleted from a Postgres database are not actually deleted immediately, but rather only flagged as deleted so that they’ll still be available to any open snapshots that may still have use for them. When they’re no longer needed in any snapshot, a VACUUM process will perform a pass and safely delete them more permanently.
The flags that power MVCC are visible as “hidden” columns on any Postgres table called xmin and xmax. Let’s take a simple example where we’re holding a few unworked jobs in a Que table:
term-A-# select xmin, xmax, job_id from que_jobs limit 5;
xmin | xmax | job_id
-------+------+--------
89912 | 0 | 25865
89913 | 0 | 25866
89914 | 0 | 25867
89915 | 0 | 25868
89916 | 0 | 25869
(5 rows)
Every write transaction in Postgres is assigned a transaction ID (xid). The xmin column defines the minimum transaction ID for which a particular row becomes visible (i.e. the xid where it was created). xmax defines the maximum xid bound that the row is available. As above, for a row that’s still available to any new transaction, that number is set to 0.
If we start a new transaction from a different console:
term-B-# start transaction isolation level serializable;
START TRANSACTION
Then remove one of the jobs from outside that new transaction:
term-A-# delete from que_jobs where job_id = 25865;
DELETE 1
We can see that the removed row (which is still visible from our second transaction), now has its xmax set:
term-B-# select xmin, xmax, job_id from que_jobs limit 5;
xmin | xmax | job_id
-------+-------+--------
89912 | 90505 | 25865
89913 | 0 | 25866
89914 | 0 | 25867
89915 | 0 | 25868
89916 | 0 | 25869
(5 rows)
A new operation in the database will be assigned a xid af 90506 or higher, and job_id 25865 will be invisible to it.
Descending the B-tree
The standard Postgres index is implemented as a B-tree which is searched to find TIDs (tuple identifiers) that are stored in its leaves. These TIDs then map back to physical locations of rows within the table which Postgres can use to extract the full tuple.
The one key piece of information here is that a Postgres index doesn’t generally contain tuple visibility information 1. To know whether a tuple is still visible to the in-progress transaction, it must be extracted from the heap and have its visibility checked.
The Postgres codebase is large enough that pointing to a single place to outline this detail in the implementation is difficult, but index_getnext as shown below is a pretty important piece of it. Its job is to scan any type of index in a generic way and extract a tuple that matches the conditions of an incoming query. Most of the body is wrapped in a continuous loop that first calls into index_getnext_tid which will descend the B-tree to find an appropriate TID. After one is retrieved, it’s passed off to index_fetch_heap, which will fetch the full tuple from the heap, and among other things check its visibility against the current snapshot (a snapshot reference is stored as part of the IndexScanDesc type) 2.
/* ----------------
* index_getnext - get the next heap tuple from a scan
*
* The result is the next heap tuple satisfying the scan keys and the
* snapshot, or NULL if no more matching tuples exist.
*
* On success, the buffer containing the heap tup is pinned (the pin will be
* dropped in a future index_getnext_tid, index_fetch_heap or index_endscan
* call).
*
* Note: caller must check scan->xs_recheck, and perform rechecking of the
* scan keys if required. We do not do that here because we don't have
* enough information to do it efficiently in the general case.
* ----------------
*/
HeapTuple
index_getnext(IndexScanDesc scan, ScanDirection direction)
{
HeapTuple heapTuple;
ItemPointer tid;
for (;;)
{
if (scan->xs_continue_hot)
{
/*
* We are resuming scan of a HOT chain after having returned an
* earlier member. Must still hold pin on current heap page.
*/
Assert(BufferIsValid(scan->xs_cbuf));
Assert(ItemPointerGetBlockNumber(&scan->xs_ctup.t_self) ==
BufferGetBlockNumber(scan->xs_cbuf));
}
else
{
/* Time to fetch the next TID from the index */
tid = index_getnext_tid(scan, direction);
/* If we're out of index entries, we're done */
if (tid == NULL)
break;
}
/*
* Fetch the next (or only) visible heap tuple for this index entry.
* If we don't find anything, loop around and grab the next TID from
* the index.
*/
heapTuple = index_fetch_heap(scan);
if (heapTuple != NULL)
return heapTuple;
}
return NULL; /* failure exit */
}
This insight along with performing some basic profiling to check it leads us to the reason our locking performance suffers so much given a long running transaction. As dead tuples continue to accumulate in the index, Postgres enters a hot loop as it searches the B-tree, comes up with an invisible tuple, and repeats the process again and again, surfacing empty-handed every time. By the end of the experiment illustrated in the charts above, every worker trying to lock a job would cycle through this loop 100,000 times. Worse yet, every time a job is successfully worked a new dead tuple is left in the index, making the next job that much harder to lock.
Illustrated visually, a lock under ideal conditions searches the job queue’s B-tree and immediately finds a job to lock:

In the degenerate case, a search turns up a series of dead tuples that must be scanned through until a live job is reached:

A job queue’s access pattern is particularly susceptible to this kind of degradation because all this work gets thrown out between every job that’s worked. To minimize the amount of time that a job sits in the queue, queueing systems tend to only grab one job at a time which leads to short waiting periods during optimal performance, but particularly pathologic behavior during the worse case scenario.
Solutions
Predicate specificity
Stated plainly, our root problem is that the job table’s index has become less useful to the point where using it isn’t much faster than a full sequential scan. Even after selecting rows based on the predicates we’ve specified, Postgres still has to seek through thousands of dead rows before finally arriving at something that it can use.
Referencing the locking SQL above, we can hypothesize that it may be the fairly minimal constraint on only queue name and run_at that’s making the index search so inefficient. In the degraded case, all dead rows that have already been worked will match both these conditions:
WHERE queue = $1::text
AND run_at <= now()
We know that the third field in the Que table’s primary key is job_id; what if we could modify the predicate above to take it into account as well? If we could supply a job_id that was even reasonably fresh, that should be enough to increase the specificity of the query enough to skip thousands of dead rows that we might have otherwise had to examine.
Illustrated visually, the locking function is able to skip the bulk of the dead rows because its B-tree search takes it to a live job right away:

Because Que works jobs in the order that they came into the queue, having workers re-use the identifier of the last job they worked might be a simple and effective way to accomplish this. Here’s the basic pseudocode for a modified work loop:
last_job_id = nil
loop do
# if last_job_id is nil, the extra constraint on job_id is left out of the
# lock query
job = lock_job(last_job_id)
work_job(job)
last_job_id = job.id
end
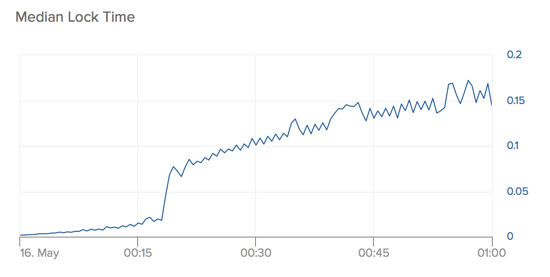
Let’s apply an equivalent patch to Que and see how it fairs. Here’s oldest transaction time vs. queue count after the patch:
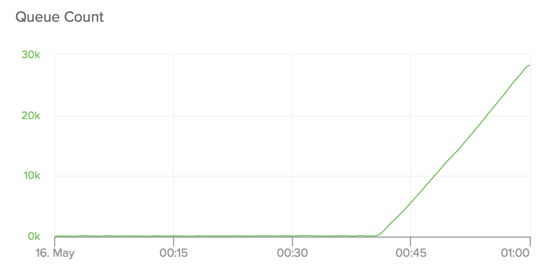
And for comparison, here’s what it looked like before the patch:
We can see above that the patched version of Que performs optimally for roughly twice as long under degraded conditions. It eventually hockeysticks as well, but only after maintaining a stable queue for a considerable amount of time 3. We found that a database’s capacity to work under degraded conditions was partly a function of database size too: the tests above were run on a heroku-postgresql:standard-2, but a heroku-postgresql:standard-7 with the patched version of Que was able to maintain near zero queue for the entire duration of the experimental run, while the unpatched version degraded nearly identically to its companion on the smaller database.
Lock jitter
An astute reader may have noticed that our proposed revision of the locking algorithm above introduces a new problem. If a worker dies or a transaction commits a job ID that’s out of order, it’s possible for all online workers to have moved onto last_job_ids that are all higher than one of the unworked jobs left in the queue, leaving that job with a low job ID in an indefinite limbo.
To account for this problem our patch to Que introduces a time-based form of locking jitter. Every so often each worker will forget their last_job_id and select any available job from the queue. If a long-lived transaction is ongoing, these selects without a job_id will be significantly more expensive, but they will be run infrequently enough that our job queue should still be able to remain stable overall.
An amended form of the new work loop pseudocode that performs some jitter of this sort might look like this:
last_job_id = nil
start = now()
loop do
# lock jitter
if now() > start + 60.seconds
last_job_id = nil
start = now()
end
job = lock_job(last_job_id)
work_job(job)
last_job_id = job.id
end
Lock multiple jobs
An alternative approach to solving the same problem might be to have each worker lock more than one job at a time, which distributes the cost of taking the lock. Its disadvantage is that the overall time to get a job worked may suffer because jobs can get “stuck” behind a long-running job that happened to come out ahead of them in the same batch.
Batch jobs to Redis
Yet another approach might be to drop your Postgres-based queues completely and instead save jobs to a pending_jobs table in your database. A background process could then loop through and select jobs from this table en masse and feed them out to a Redis-backed job queue like Sidekiq. This would allow your project to keep the nice database-based property of transactional consistency, but the background worker selecting jobs in bulk would keep the implementation orders of magnitude more resistant to long-lived transactions than Que or Queue Classic.
The extra hop required for the pending_jobs table may make this implementation a little slower than a Postgres-based queue operating under ideal conditions, but it could probably be optimized so as not to be too costly.
Lessons learnt
Given a full understanding of problems with long-lived transactions in Postgres, a tempting (but overly simplistic) takeaway might be that Postgres isn’t a good fit for a job queue. This is at least partly correct, but it’s worth remembering that although a job queue may be the least optimal situation, similar problems can develop for any sufficiently hot Postgres table.
First and foremost, it’s worth considering putting together a Postgres supervisor that keeps an eye on transactions happening on the leader and all followers, and executes a pg_terminate_backend on anything that’s been alive for too long. Postgres also provides a built-in setting called statement_timeout that’s worth enabling as well, but which is insufficient in itself because it can fail under a variety of conditions (like a user overriding it manually).
Finally, I’d highly encourage database use to stay within the operational boundaries of a single component. This has already been addressed elsewhere online, but the correct way for components to intercommunicate is via well-defined and safe-by-default APIs. If we hadn’t shared our database with other teams who had a relatively poor understanding as to what they were running on it, this problem would have taken significantly longer to appear.
Summary
Long lived transactions on a Postgres database can cause a variety of problems for hot tables including a job queue. Given a reasonable understanding of how Postgres’ B-tree and tuple visibility implementation works, we can vary our job locking approach to improve this situation, but not eliminate it completely. For optimal results, monitor long-lived transactions within Postgres clusters and don’t share databases across component or team boundaries.
Acknowledgements
Many thanks to my colleague Daniel Farina for postulating the original hypothesis suggesting the precise failure mechanic of QC and Que, and my colleague Peter Geoghegan for verifying our findings with relation to Postgres and suggesting improvements to this article for accuracy.