For years now, I’ve been having a crisis of faith in interpreted languages. They’re fast and fun to work in at small scale, but when you have a project that gets big, their attractive veneer quickly washes away. A big Ruby or JavaScript (just to name a few) program in production is a never ending game of whack-a-mock – you fix one problem only to find a new one somewhere else. No matter how many tests you write, or how well-disciplined your team, any new development is sure to introduce a stream of bugs that will need to be shored up over the course of months or years.
Central to the problem are the edges. People will reliably do a good job of building and testing the happy paths, but as humans we’re terrible at considering the edge conditions, and it’s those edges and corners that cause trouble over the years that a program is in service.
Constraints like a compiler and a discerning type system are tools that help us to find and think about those edges. There’s a spectrum of permissiveness across the world of programming languages, and my thesis right now is that more time spent in development satisfying a language’s rules will lead to less time spent fixing problems online.
Rust
If it’s possible to build more reliable systems with programming languages with stricter constraints, what about languages with the strongest constraints? I’ve skewed all the way to the far end of the spectrum and have been building a web service in Rust, a language infamous for its uncompromising compiler.
The language is still new and somewhat impractical. It’s been a slog learning its rules around types, ownership, and lifetimes. Despite the difficulty, it’s been an interesting learning experience throughout, and it’s working. I run into fewer forgotten edge conditions and runtime errors are way down. Broad refactoring is no longer terror-inducing.
Here we’ll run through some of the more novel ideas and features of Rust, its core libraries, and various frameworks that make this possible.
The foundation
I built my service on actix-web, a web
framework layered on actix, an actor library for
Rust. actix is similar to what you might see in a
language like Erlang, except that it adds another degree of
robustness and speed by making heavy use of Rust’s
sophisticated type and concurrency systems. For example,
it’s not possible for an actor to receive a message that it
can’t handle at runtime because it would have been
disallowed at compile-time.
There’s a small chance that you’ll recognize the name
because actix-web has made its way to the top of the
TechEmpower benchmarks. Programs built for
these sorts of benchmarks often turn out to be a little
contrived due to their optimizations, but its now contrived
Rust code that’s sitting right up at the top of the list
with contrived C++ and Java code. But regardless of how you
feel about the validity of benchmark programs, the takeaway
is that actix-web is fast.
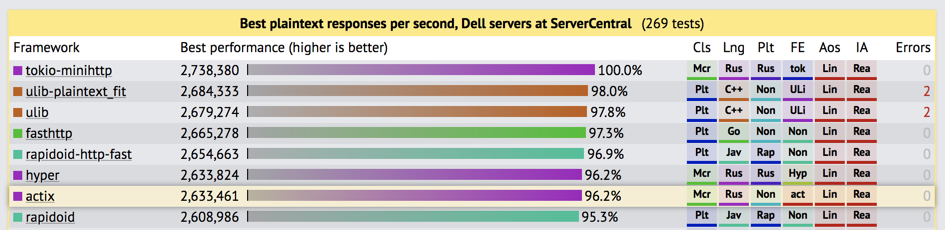
The author of actix-web (and actix) commits a
prodigious amount of code – the project is only about six
months old, and not only is already more feature-complete
and with better APIs than web frameworks seen in other open
source languages, but more so than many of the frameworks
bankrolled by large organizations with huge development
teams. Niceties like HTTP/2, WebSockets, steaming
responses, graceful shutdown, HTTPS, cookie support, static
file serving, and good testing infrastructure are readily
available out of the box. The documentation is still a bit
rough, but I’ve yet to run into a single bug.
Diesel and compile-time query checking
I’ve been using diesel as an ORM to talk to
Postgres. The most comforting thing about the project is
that it’s an ORM written by someone with a lot of past
experience with building ORMs, having spent considerable
time in the trenches with Active Record. Many of the
pitfalls common to earlier generations of ORMs have been
avoided – for example, diesel doesn’t try to pretend
that SQL dialects across every major database are the same,
it excludes a custom DSL for migrations (raw SQL is used
instead), and it doesn’t do automagical connection
management at the global level. It does bake powerful
Postgres features like upsert and jsonb right into the
core library, and provides powerful safety mechanics
wherever possible.
Most of my database queries are written using diesel’s
type-safe DSL. If I misreference a field, try to insert a
tuple into the wrong table, or even produce an impossible
join, the compiler tells me about it. Here’s a typical
operation (in this case, a Postgres batch INSERT INTO ...
ON CONFLICT ..., or “upsert”):
time_helpers::log_timed(&log.new(o!("step" => "upsert_episodes")), |_log| {
Ok(diesel::insert_into(schema::episode::table)
.values(ins_episodes)
.on_conflict((schema::episode::podcast_id, schema::episode::guid))
.do_update()
.set((
schema::episode::description.eq(excluded(schema::episode::description)),
schema::episode::explicit.eq(excluded(schema::episode::explicit)),
schema::episode::link_url.eq(excluded(schema::episode::link_url)),
schema::episode::media_type.eq(excluded(schema::episode::media_type)),
schema::episode::media_url.eq(excluded(schema::episode::media_url)),
schema::episode::podcast_id.eq(excluded(schema::episode::podcast_id)),
schema::episode::published_at.eq(excluded(schema::episode::published_at)),
schema::episode::title.eq(excluded(schema::episode::title)),
))
.get_results(self.conn)
.chain_err(|| "Error upserting podcast episodes")?)
})
More complex SQL is difficult to represent using the DSL,
but luckily there’s a great alternative in the form of
Rust’s built-in include_str! macro. It ingests a file’s
contents during compilation, and we can easily hand them
off them to diesel for parameter binding and execution:
diesel::sql_query(include_str!("../sql/cleaner_directory_search.sql"))
.bind::<Text, _>(DIRECTORY_SEARCH_DELETE_HORIZON)
.bind::<BigInt, _>(DELETE_LIMIT)
.get_result::<DeleteResults>(conn)
.chain_err(|| "Error deleting directory search content batch")
The query lives in its own .sql file:
WITH expired AS (
SELECT id
FROM directory_search
WHERE retrieved_at < NOW() - $1::interval
LIMIT $2
),
deleted_batch AS (
DELETE FROM directory_search
WHERE id IN (
SELECT id
FROM expired
)
RETURNING id
)
SELECT COUNT(*)
FROM deleted_batch;
We lose compile-time SQL checking with this approach, but we gain direct access to the raw power of SQL’s semantics, and great syntax highlighting in your favorite editor.
A fast (but not the fastest) concurrency model
actix-web is powered by tokio, a fast event
loop library that’s the cornerstone of Rust’s concurrency
story 1. When starting an HTTP server, actix-web spawns
a number of workers equal to the number of logical cores on
the server, each in its own thread, and each with its own
tokio reactor.
HTTP handlers can be written in a variety of ways. We might write one that returns content synchronously:
fn index(req: HttpRequest) -> Bytes {
...
}
This will block the underlying tokio reactor until it’s
finished, which is appropriate in situations where no other
blocking calls need to be made; for example, rendering a
static view from memory, or responding to a health check.
We can also write an HTTP handler that returns a boxed future. This allows us to chain together a series of asynchronous calls to ensure that the reactor’s never needlessly blocked.
fn index(req: HttpRequest) -> Box<Future<Item=HttpResponse, Error=Error>> {
...
}
Examples of this might be responding with a file that we’re
reading from disk (blocking on I/O, albeit minimally), or
waiting on a response from our database. While waiting on a
future’s result, the underlying tokio reactor will
happily fulfill other requests.

Synchronous actors
Support for futures in Rust is widespread, but not
universal. Notably, diesel doesn’t support asynchronous
operations, so all its operations will block. Using it from
directly within an actix-web HTTP handler would lock up
the thread’s tokio reactor, and prevent that worker from
serving other requests until the operation finished.
Luckily, actix has a great solution for this problem in
the form of synchronous actors. These are actors that
expect to run their workloads synchronously, and so each is
assigned its own dedicated OS-level thread. The
SyncArbiter abstraction is provided to easily start a
number of copies of one type of actor, each sharing a
message queue so that it’s easy to send work to the set
(referenced as addr below):
// Start 3 `DbExecutor` actors, each with its own database
// connection, and each in its own thread
let addr = SyncArbiter::start(3, || {
DbExecutor(SqliteConnection::establish("test.db").unwrap())
});
Although operations within a synchronous actor are blocking, other actors in the system like HTTP workers don’t need to wait for any of it to finish – they get a future back that represents the message result so that they can do other work.
In my implementation, fast workloads like parsing
parameters and rendering views is performed inside
handlers, and synchronous actors are never invoked if they
don’t need to be. When a response requires database
operations, a message is dispatched to a synchronous actor,
and the HTTP worker’s underlying tokio reactor serves
other traffic while waiting for the future to resolve. When
it does, it renders an HTTP response with the result, and
sends it back to the waiting client.
Connection management
At first glance, introducing synchronous actors into the system might seem like purely a disadvantage because they’re an upper bound on parallelism. However, this limit can also be an advantage. One of the first scaling problems you’re likely to run into with Postgres is its modest limits around the maximum number of allowed simultaneous connections. Even the biggest instances on Heroku or GCP (Google Cloud Platform) max out at 500 connections, and the smaller instances have limits that are much lower (my small GCP database limits me to 25). Big applications with coarse connection management schemes (e.g., Rails, but also many others) tend to resort to solutions like PgBouncer to sidestep the problem.
Specifying the number of synchronous actors by extension also implies the maximum number of connections that a service will use, which leads to perfect control over its connection usage.

I’ve written my synchronous actors to check out individual
connections from a connection pool (r2d2) only
when starting work, and check them back in after they’re
done. When the service is idle, starting up, or shutting
down, it uses zero connections. Contrast this to many web
frameworks where the convention is to open a database
connection as soon as a worker starts up, and to keep it
open as long as the worker is alive. That approach has a
~2x connection requirement for graceful restarts because
all workers being phased in immediately establish a
connection, even while all workers being phased out are
still holding onto one.
The ergonomic advantage of synchronous code
Synchronous operations aren’t as fast as a purely asynchronous approach, but they have the benefit of ease of use. It’s nice that futures are fast, but getting them properly composed is time consuming, and the compiler errors they generate if you make a mistake are truly the stuff of nightmares, which leads to a lot of time spent debugging.
Writing synchronous code is faster and easier, and I’m personally fine with slightly suboptimal runtime speed if it means I can implement more core domain logic, more quickly.
Slow, but only relative to "very, VERY fast"
That might sound disparaging of this model’s performance characteristics, but keep in mind that it’s only slow compared to a purely-asynchronous stack (i.e., futures everywhere). It’s still a conceptually sound concurrent model with real parallelism, and compared with almost any other framework and programming language, it’s still really, really fast. I write Ruby in my day job, and compared to our thread-less model (normal for Ruby because the GIL constrains thread performance) using forking processes on a VM without a compacting GC, we’re talking orders of magnitude better speed and memory efficiency, easily.
At the end of the day, your database is going to be a bottleneck for parallelism, and the synchronous actor model supports about as much parallelism as we can expect to get from it, while also supporting maximum throughput for any actions that don’t need database access.
Error handling
Like any good Rust program, APIs almost everywhere
throughout return the Result type. Futures plumb through
their own version of Result containing either a
successful result or an error.
I’m using error-chain to define my errors. Most are internal, but I’ve defined a certain group with the explicit purpose of being user facing:
error_chain!{
errors {
//
// User errors
//
BadRequest(message: String) {
description("Bad request"),
display("Bad request: {}", message),
}
}
}
When a failure should be surfaced to a user, I make sure to map it to one of my user error types:
Params::build(log, &request).map_err(|e|
ErrorKind::BadRequest(e.to_string()).into()
)
After waiting on a synchronous actor and after attempting
to construct a successful HTTP response, I potentially
handle a user error and render it. The implementation turns
out to be quite elegant (note that in future composition,
then differs from and_then in that it handles a success
or a failure by receiving a Result, as opposed to
and_then which only chains onto a success):
let message = server::Message::new(&log, params);
// Send message to synchronous actor
sync_addr
.send(message)
.and_then(move |actor_response| {
// Transform actor response to HTTP response
}
.then(|res: Result<HttpResponse>|
server::transform_user_error(res, render_user_error)
)
.responder()
Errors not intended to be seen by the user get logged and
actix-web surfaces them as a 500 Internal server error
(although I’ll likely add a custom renderer for those too
at some point).
Here’s transform_user_error. A render function is
abstracted so that we can reuse this generically between an
API that renders JSON responses, and a web server that
renders HTML.
pub fn transform_user_error<F>(res: Result<HttpResponse>, render: F) -> Result<HttpResponse>
where
F: FnOnce(StatusCode, String) -> Result<HttpResponse>,
{
match res {
Err(e @ Error(ErrorKind::BadRequest(_), _)) => {
// `format!` activates the `Display` traits and shows our error's `display`
// definition
render(StatusCode::BAD_REQUEST, format!("{}", e))
}
r => r,
}
}
Middleware
Like web frameworks across many languages, actix-web
supports middleware. Here’s a simple one that initializes a
per-request logger and installs it into the request’s
extensions (a collection of request state that will live
for as long as the request does):
pub mod log_initializer {
pub struct Middleware;
pub struct Extension(pub Logger);
impl<S: server::State> actix_web::middleware::Middleware<S> for Middleware {
fn start(&self, req: &mut HttpRequest<S>) -> actix_web::Result<Started> {
let log = req.state().log().clone();
req.extensions().insert(Extension(log));
Ok(Started::Done)
}
fn response(
&self,
_req: &mut HttpRequest<S>,
resp: HttpResponse,
) -> actix_web::Result<Response> {
Ok(Response::Done(resp))
}
}
/// Shorthand for getting a usable `Logger` out of a request.
pub fn log<S: server::State>(req: &mut HttpRequest<S>) -> Logger {
req.extensions().get::<Extension>().unwrap().0.clone()
}
}
A nice feature is that middleware state is keyed to a
type instead of a string (like you might find with Rack
in Ruby for example). This not only has the benefit of type
checking at compile-time so you can’t mistype a key, but
also gives middlewares the power to control their
modularity. If we wanted to strongly encapsulate the
middleware above we could remove the pub from Extension
so that it becomes private. Any other modules that tried to
access its logger would be prevented from doing so by
visibility checks in the compiler.
Asynchrony all the way down
Like handlers, actix-web middleware can be asynchronous
by returning a future instead of a Result. This would,
for example, let us to implement a rate limiting middleware
that made a call out to Redis in a way that doesn’t block
the HTTP worker. Did I mention that actix-web is pretty
fast?
HTTP testing
actix-web documents a few recommendations for HTTP
testing methodologies. I settled on a series
of unit tests that use TestServerBuilder to compose a
minimal app containing a single target handler, and then
execute a request against it. This is a nice compromise
because despite tests being minimal, they nonetheless
exercise an end-to-end slice of the HTTP stack, which makes
them fast and complete:
#[test]
fn test_handler_graphql_get() {
let bootstrap = TestBootstrap::new();
let mut server = bootstrap.server_builder.start(|app| {
app.middleware(middleware::log_initializer::Middleware)
.handler(handler_graphql_get)
});
let req = server
.client(
Method::GET,
format!("/?query={}", test_helpers::url_encode(b"{podcast{id}}")).as_str(),
)
.finish()
.unwrap();
let resp = server.execute(req.send()).unwrap();
assert_eq!(StatusCode::OK, resp.status());
let value = test_helpers::read_body_json(resp);
// The `json!` macro is really cool:
assert_eq!(json!({"data": {"podcast": []}}), value);
}
I make heavy use of serde_json’s (the standard Rust JSON
encoding and decoding library) json! macro, used on the
last line in the code above. If you look closely, you’ll
notice that the in-line JSON is not a string – json!
lets me write actual JSON notation right into my code that
gets checked and converted to a valid Rust structure by the
compiler. This is by far the most elegant approach to
testing HTTP JSON responses that I’ve seen across any
programming language, ever.
Summary: is Rust the future for resiliency?
It’d be fair to say that I could’ve written an equivalent service in Ruby in a tenth of the time it took me to write this one in Rust. Some of that is Rust’s learning curve, but a lot of it isn’t – the language is succinct to write, but appeasing the compiler is often a long and frustrating process.
That said, over and over I’ve experienced passing that final hurdle, running my program, and experiencing a Haskell-esque euphoria in seeing it work exactly as I’d intended it to. Contrast that to an interpreted language where you get it running on your 15th try, and even then, the edge conditions are almost certainly still wrong. Rust also makes big changes possible – it’s not unusual for me to refactor a thousand lines at a time, and once again, have the program run perfectly afterwards. Anyone who’s seen a large program in an interpreted language at production-scale knows that you never deploy a sizable refactor to an important service except in miniscule chunks – anything else is too risky.
Should you write your next web service in Rust? I don’t know yet, but we’re getting to the point now where you should at least consider it.
