One pleasant surprise of Stripe’s internal culture was the existence of a number of a recreational clubs (mostly manifested as internal Slack channels) – and specifically one for running. At least some part of the group would assemble regularly and go out and tackle runs around San Francisco’s Mission district where the Stripe office is located.
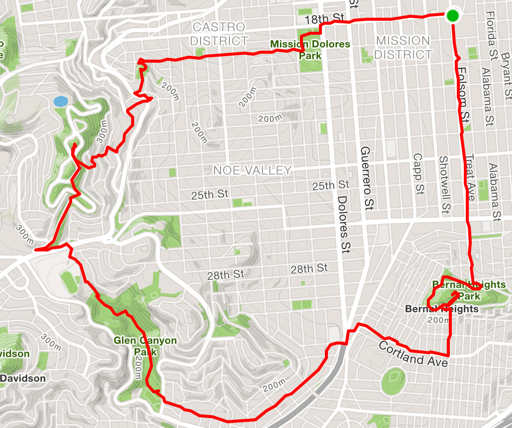
By the time I joined, the club already had a couple of well-established traditional loops which included some real beasts. Probably the most notable is the (internally) renowned “Triple Peaks”, a journey south from the office, up Bernal Heights, west through Glen Canyon Park, and with a final ascent up Twin Peaks before returning through the Castro and the Mission. My usual routes around Heroku’s office in SOMA included pretty healthy total distances, but nowhere near this level of elevation gain or variation in terrain.
Analysis
Between the new social pressure and the new available routes, over the last month I’ve certainly felt like I was running more, but it would be nice to know for sure. Let’s try to use Postgres to crunch some data and get a definitive answer.
In order to do a comparison, I want to run the same query that aggregates my
distance from two different points in time: once for my time at Stripe and once
for my previous life. A great fit for this operation is a Postgres prepared
statement; an underused and surprising simple to operate tool that should be
part of every Postgres user’s kit. It works through the use of the PREPARE ...
AS command to create a server-side object that’s parsed and pre-analyzed for
execution, and then following up with an EXECUTE command which runs the
planner and executes the statement.
I’ll be using a database created for my Black Swan project, which periodically scrapes my social media services. I routinely log all my runs with Strava, and the data here is being pulled from their API specifically.
Here we define our prepared statement named running_totals with a time
parameter indicating the day we want to start measuring from and a duration (or
interval in Postgres parlance) that specifies how far to go back in time:
PREPARE running_totals AS
SELECT sum((metadata -> 'distance')::decimal) AS distance,
sum((metadata -> 'total_elevation_gain')::decimal) AS elevation
FROM events
WHERE type = 'strava'
AND metadata -> 'type' = 'Run'
AND date_trunc('day', occurred_at) <= date_trunc('day', $1::timestamptz)
AND date_trunc('day', occurred_at) >= date_trunc('day', $1::timestamptz)
- $2::interval;
You’ll notice here that I’ll be type casting the parameter with ::timestamptz
and ::interval so that I can send in strings as input. Postgres has an
amazing ability to cast loosely formatted strings like September 9, 2015 and
30 days into concrete times and durations that we can work with in our
calculations.
For the period before Stripe, I’ll use the date of my final run while working my last job and measure 30 days from there into the past:
# EXECUTE running_totals('September 9, 2015', '30 days');
distance | elevation
----------+-----------
113854.1 | 0.0
For Stripe, I’ll measure from today for the same period:
# EXECUTE running_totals('October 24, 2015', '30 days');
distance | elevation
----------+-----------
219835.5 | 5176.1
A pretty encouraging difference of 220 km vs 114 km, or an almost 100% increase! But aside from just distance, we also see a pretty nice improvement in the elevation numbers where I’ve managed to accumulate over 5 km of vertical gain in 30 days. This represents my graduation from flat runs along San Francisco’s waterfront to the hilly regions closer to the Mission. Hopefully these numbers won’t prove to be a statistical anomaly as I leave my honeymoon phase at the company.