The term “webhook” was coined back in 2007 by Jeff Lindsay as a “hook” (or callback) for the web; meant to be a general purpose system to allow Internet systems to be composed in the same spirit as the Unix pipe. By speaking HTTP and being symmetrical to common HTTP APIs, they were an elegant answer to a problem without many options at the time – WebSockets wouldn’t be standardized until 2011 and would only see practical use much later. Most other contemporary streaming options were still only a distant speck on the horizon.
For a few very common APIs like GitHub, Slack, or Stripe, the push stream available over webhooks might be one of the best-known features. They’re reliable, can be used to configure multiple receivers that receive customized sets of events, and they even work for accounts connected via OAuth, allowing platforms built on the APIs to tie into the activity of their users. They’re a great feature and aren’t going anywhere anytime soon, but they’re also far from perfect. In the spirit of avoiding accidental evangelism, here we’ll talk about whether they’re a good pattern for new API providers to emulate.
A basic case for webhooks
First, let’s take a look at why webhooks are useful. While REST APIs commonly make up the backbone for accessing and manipulating information in a web platform, webhooks are often used as a second facet that augments it by streaming real-time updates.
Say you’re going to write a mini-CI service that will build any branches that are opened via pull request on one of your GitHub repositories. Like Travis, we want it to be able to detect a pull request, and then assign it a status check icon that will only be resolved when the build completes.
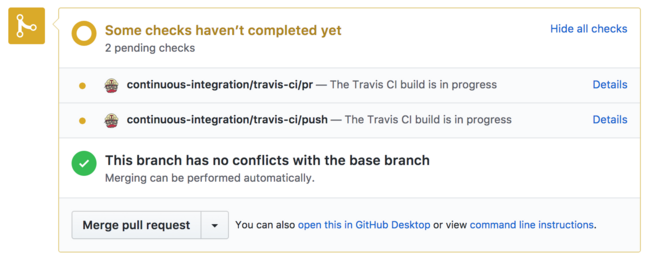
GitHub has a status API that can assign or
update statuses associated with a given commit SHA. With
just a REST API, we’d have to poll the list endpoint every
few seconds to know when new pull requests come in. Luckily
though, there’s much better way: we can listen on for
GitHub’s pull_request webhook, and it’ll notify us when
anything changes.
Our CI service listens for pull_request webhooks, creates
a new status via the REST API when it sees one, and then
updates that status when its corresponding build succeeds
or fails. It’s able to add status checks in a timely manner
(ideally users see a pending status the moment they
open a new pull), and with no inefficient polling involved.

The virtues of user ergonomics
As we see above webhooks are convenient and work pretty well, but that said, they’re far from perfect in a number of places. Let’s look at a few ways that using them can be a little painful.
Endpoint provisioning and management
Getting an HTTP endpoint provisioned to receive a webhook isn’t technically difficult, but it can be bureaucratically so.
The classic example is the large enterprise where getting a new endpoint exposed to the outside world might be a considerable project involving negotiations with infrastructure and security teams, requisitioning new hardware, and piles of paperwork. In the worst cases, webhooks might be wholly incompatible with an organization’s security model where user data is uncompromisingly kept within a secured perimeter at all times.

Development and testing are also difficult cases. There’s no perfectly fluid way of getting an endpoint from a locally running environment exposed for a webhook provider to access. Programs like Ngrok are good options, but still add a step and complication that wouldn’t be necessary with an alternate scheme.
Uncertain security
Because webhook endpoints are publicly accessible HTTP APIs, it’s up to providers to build in a security scheme to ensure that an attacker can’t issue malicious requests containing forged payloads. There’s a variety of commonly seen techniques:
- Webhook signing: Sign webhook payloads and send the signature via HTTP header so that users can verify it.
- HTTP authentication: Force users to provide HTTP basic auth credentials when they configure endpoints to receive webhooks.
- API retrieval: Provide only an event identifier in webhook payload and force recipients to make a synchronous API request to get the message’s full contents.

Good security is possible, but a fundamental problem with webhooks is that it’s difficult as a provider to ensure that your users are following best practices. Of the three options above, only the third guarantees strong security; even if you provide signatures you can’t know for sure that your users are verifying them, and if forced to provide HTTP basic auth credentials, many users will opt for weak ones, which combined with endpoints that are probably not rate limited, leave them vulnerable to brute force attacks.
This is in sharp contrast to synchronous APIs where a provider gets to choose exactly what API keys will look like and dictate best practices around how they’re issued and how often they’re rotated.
Development and testing
It’s relatively easy to provide a stub or live testmode for a synchronous API, but a little more difficult for webhooks because the user needs some mechanic to request that a test webhook be sent.
At Stripe, we provide a “Send test webhook” function from the dashboard. This provides a reasonable developer experience in that at least testing an endpoint is possible, but it’s manual and not especially conducive to being integrated into an automated test suite.
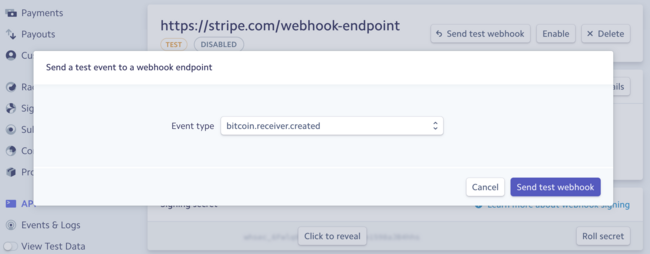
Most developers will know that manual testing is never enough. It’ll get a program working today and that program will probably stay working tomorrow, but without more comprehensive CI something’s likely to break given a long enough timeline.
No ordering guarantees
Transmission failures, variations in latency, and quirks in the provider’s implementation means that even though webhooks are sent to an endpoint roughly ordered, there are no guarantees that they’ll be received that way.
For example, a provider might send a created event for
resource123, but a send failure causes it to be queued
for retransmission. In the meantime, resource123 is
deleted and its deleted event sends correctly. Later, the
created event is also sent, but by then the consumer’s
received it after its corresponding deleted. A lot of the
time this isn’t a big problem, but consumers must be built
to be tolerant of these anomalies.

In an ideal world, a real-time stream would be reliable enough that a consumer could use it as an ordered append-only log which could be used to manage state in a database. Webhooks are not this system.
Version upgrades
For providers that version their API like we do at Stripe, version upgrades can be a problem. Normally we allow users to explicitly request a new version with an API call so that they can verify that their integration works before upgrading their account, but with webhooks the provider has to decide in advance what version to send. Often this leads to users trying to write code that’s compatible across multiple versions, and then flipping the upgrade switch and praying that it works (when it doesn’t, the upgrade must be rolled back).
Once again, this can be fixed with great tooling, but that’s more infrastructure that a provider needs to implement for a good webhook experience. We recently added a feature that lets users configured the API version that gets sent to each of their webhook endpoints, but for a long time upgrades were a scary business.
The toil in the kitchens
Possibly a bigger problem than any of their user shortcomings is that webhooks are painful to run. Let’s look at the specifics.
Misbehavior is onerous
If a consumer endpoint is slow to respond or suddenly starts denying requests, it puts pressure on the provider’s infrastructure. A big user might have millions of outgoing webhooks and just them going down might be enough to start backing up global queues, leading to a degraded system for everyone.
Worse yet, there’s no real incentive for recipients to fix the problem because the entirety of the burden lands on the webhook provider. We’ve been stuck in positions where we have to email huge users as millions of failed webhooks pile up in the backlog with something like, “we don’t want to disable you, but please fix your systems or we’re going to have to” and hoping that they get back to us before things are really on fire.
You can put in a system where recipients have to meet certain uptime and latency SLAs or have their webhooks disabled, but once again, that needs additional tooling and documentation, and the additional restrictions won’t make your users particularly happy.
Retries
To ensure receipt, webhook system needs to be built with retry policies. A recipient could shed a single request due to an intermittent network problem, so you retry a few moments later to ensure that all messages make it through.
This is a nice feature, but is expensive and wasteful at the edges. Say for example that a user takes down one of their servers without deleting a corresponding endpoint. At Stripe, we’ll try to redeliver every generated event 72 times (once an hour for three days) before finally giving up, which could mean tens of thousands wasted connections.
You can mitigate this by disabling endpoints that look like they’re dead and sending an email to notify their owner, but again this needs to be tooled and documented. It’s a bit of a compromise because you have less tech savvy users who legitimately have a server go down for a day or two, and may later be surprised that their webhooks are no longer being delivered. You can also have endpoints that are “the living dead”: they time out most requests after tying up your clients for 30 seconds or so, but successfully respond often enough that they’re never fully disabled. These are costly to support.
Chattiness and communication (in)efficiency
Webhooks are one HTTP request for one event. You can apply a few tricks like keeping connections open to servers that you deliver to frequently to save a few round trips on transport construction (for setting up a connection and negotiating TLS), but they’re a very chatty protocol at heart.
We’ve got enough modern languages and frameworks that providers can build massively concurrent implementations with relative ease, but compared to something like streaming a few thousand events over a big connected firehose, webhooks are very inefficient.
Internal security
The servers sending webhooks are within a provider’s internal infrastructure, and depending on architecture, may be able to access other services. A common “first timer” webhooks provider mistake is to not insulate the senders from other infrastructure; allowing an attacker to probe it by configuring webhook endpoints with internal URLs.

This is mitigable (and every big provider has measures in place to do so), but webhook infrastructure will be dangerous by default.
What makes webhooks great
We’ve talked mostly about the shortfalls of webhooks, but they’ve got some nice properties too. Here are a few of the best.
Automatic load balancing
A commonly overlooked but amazing feature of webhooks is that they provide automatic load balancing and allow a consumer’s traffic to ramp up gracefully.
The alternative to webhooks is some kind of “pull” API where a provider streams events through a connection. This is mostly fine, but given enough volume, eventually some kind of partitioning scheme is going to be needed as the stream grows past the capacity of any single connection (think like you’d see in Kafka or Kinesis). Partitioning works fine, but is invariably more complicated and makes integrating more difficult. Getting consumers to upgrade from one to two partitions when the limits of a single partition are reached is really difficult.
With webhooks, scaling is almost entirely seamless for recipients. They need to make sure that their endpoints are scaled out to handle the extra load, but this is a well understood problem. Horizontal scaling combined with an off-the-shelf load balancer (DNS, HAProxy, ELBs, …) will make this relatively painless.
Lingua franca
Web servers are absolutely ubiquitous across every conceivable programming language and framework which means that everyone can receive a webhook, and without pulling down any unusual dependencies.
Webhooks are accessible in a way that more exotic technologies may never be, and that by itself is good reason to use them. Accessible technologies have a greater pool of potential developers, and that’s going to lead to more integrations. An easy API in the form of webhooks has undoubtedly helped companies like GitHub and Slack grow their platforms.
The road ahead
Lately I’ve been talking about what API paradigms might look like beyond our current world of REST, so it seems like a good time to look at some modern alternatives to webhooks.
The HTTP log
Since the inception of webhooks there’s been a few technologies that have been standardized that are well-suited for streaming changes. WebSockets and server-sent events (SSE) are two great examples.
Consumers would negotiate a stream over HTTP with the normal RESTish API, and hold onto it listening for new events from the server as long as they can. Unlike webhooks, events are easily accessible from any environment (that allows outgoing connections), fully verified, ordered, and even potentially versioned according to the consumer’s request.
A downside is that it’s the consumer’s responsibility to make requests and track where they left off. This isn’t an overly difficult requirement, but it’s likely to cause problems for at least some users as they lose their place in the stream, or don’t fetch incoming events in time. Providers would undoubtedly also have to put limits on how far back in history users are allowed to request, and have an implementation that makes sending lots of aging event data efficient.
GraphQL subscriptions
Along with queries and mutations, GraphQL supports a third type of operation called a “subscription” (see that in the spec here). A provider provides an available subscription that describes the type of events that a recipient will receive:
subscription StoryLikeSubscription($input: StoryLikeSubscribeInput) {
storyLikeSubscribe(input: $input) {
story {
likers { count }
likeSentence { text }
}
}
}
Along with an input type that recipients will use to specify the parameters of the stream:
input StoryLikeSubscribeInput {
storyId: string
clientSubscriptionId: string
}
Like with a lot of GraphQL, the specifics around implementation for subscriptions aren’t strongly defined. In a blog post announcing the feature, a Facebook engineer mentions that they receive subscription events over an MQTT topic, but lots of options for pub/sub technology are available.
GRPC streaming RPC
GRPC is a framework created by Google that enables easy remote procedure calls (RPC) from client to server across a wide variety of supported languages and platforms. It builds on top of protocol buffers, a well-vetted serialization technology that’s been around for more than a decade.
Although it’s largely used for one-off request/responses, it also supports streaming remote procedure calls where a provider can send back any number of messages before the connection is finalized. This simple Go example demonstrates roughly how it works (and keep in mind that the feature is available in GRPC’s impressive set of supported languages):
stream, err := client.ListFeatures(...)
if err != nil {
...
}
for {
feature, err := stream.Recv()
if err == io.EOF {
break
}
if err != nil {
...
}
log.Println(feature)
}
Bi-directional streams are also supported for back and forth communication over a single re-used connection.
What to do today
Webhooks are a fine system for real time streaming and providers who already offer them and have their operational dynamics figured out should probably stick with them. They work well and are widely understood.
However, between somewhat less-than-optimal developer experience and considerable operational concerns, providers who are building new APIs today should probably be considering every available option. Those who are already building systems on non-REST paradigms like GraphQL or GRPC have a pretty clear path forward, and for those who aren’t, modeling something like a log over HTTP/WebSockets/SSE might be a good way to go.